Publications
Updated list on Google Scholar
2025
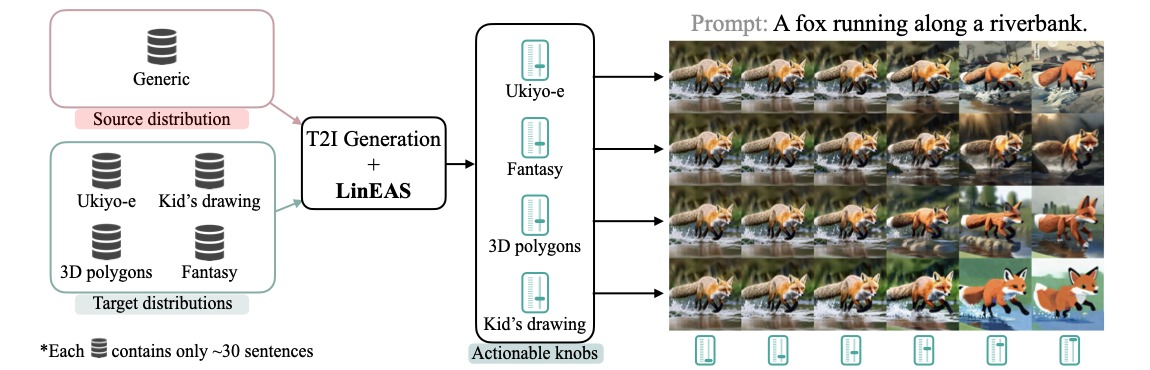
- In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025TL;DR: We introduce LinEAS, a method for controlling generative models by learning affine transformations on internal activations using optimal transport theory. Training end-to-end across all layers with just 32 unpaired samples and sparse regularization for automatic neuron selection, LinEAS achieves effective toxicity mitigation in LLMs and style control in text-to-image models without retraining
- NeurIPS spotlight
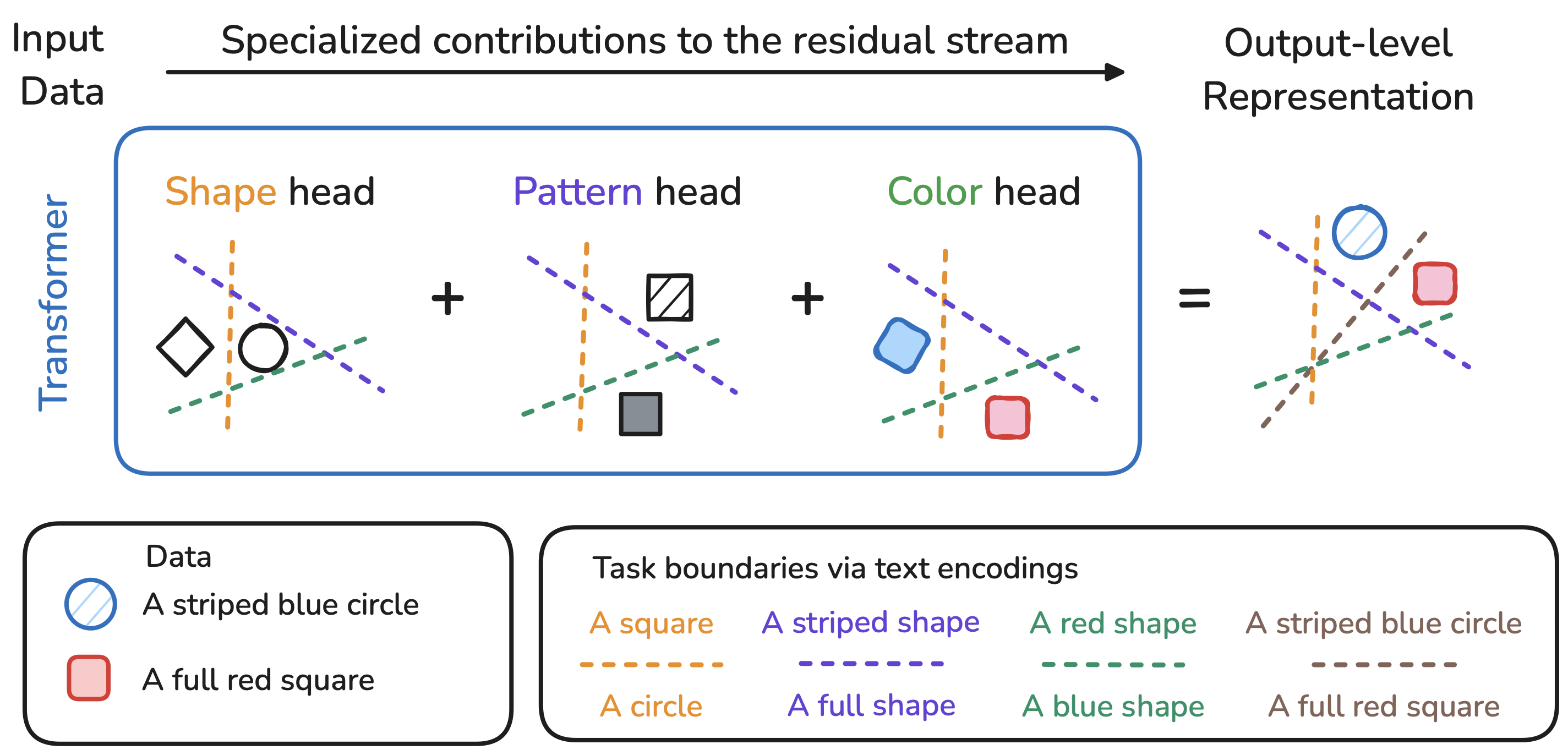
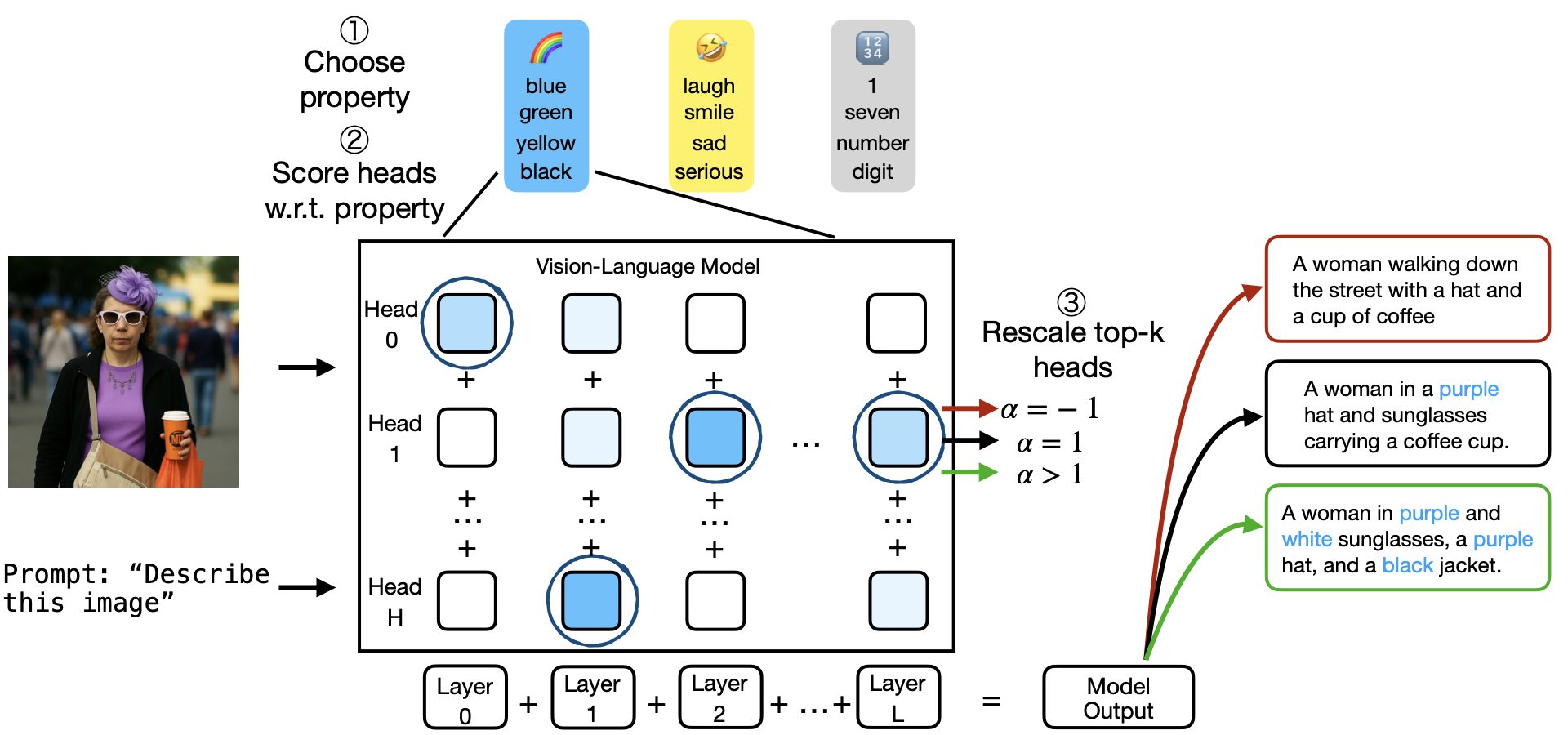 In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025TL;DR: We use Simultaneous Orthogonal Matching Pursuit to identify attention heads specialized in narrow semantic domains (colors, countries, toxicity) in large language and vision-language models. Intervening on as few as 1% of heads enables bidirectional concept control—suppressing toxic content by 34-51% or enhancing target attributes—without any training
In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025TL;DR: We use Simultaneous Orthogonal Matching Pursuit to identify attention heads specialized in narrow semantic domains (colors, countries, toxicity) in large language and vision-language models. Intervening on as few as 1% of heads enables bidirectional concept control—suppressing toxic content by 34-51% or enhancing target attributes—without any training - TMLR, 2025TL;DR: We discover that attention head representations in vision transformers lie on low-dimensional manifolds where principal components encode specialized semantics (letters, locations, animals, etc.). By selectively amplifying task-relevant principal components through learned anisotropic scaling (ResiDual), we achieve fine-tuning level performance with up to 4 orders of magnitude fewer parameters than full fine-tuning.
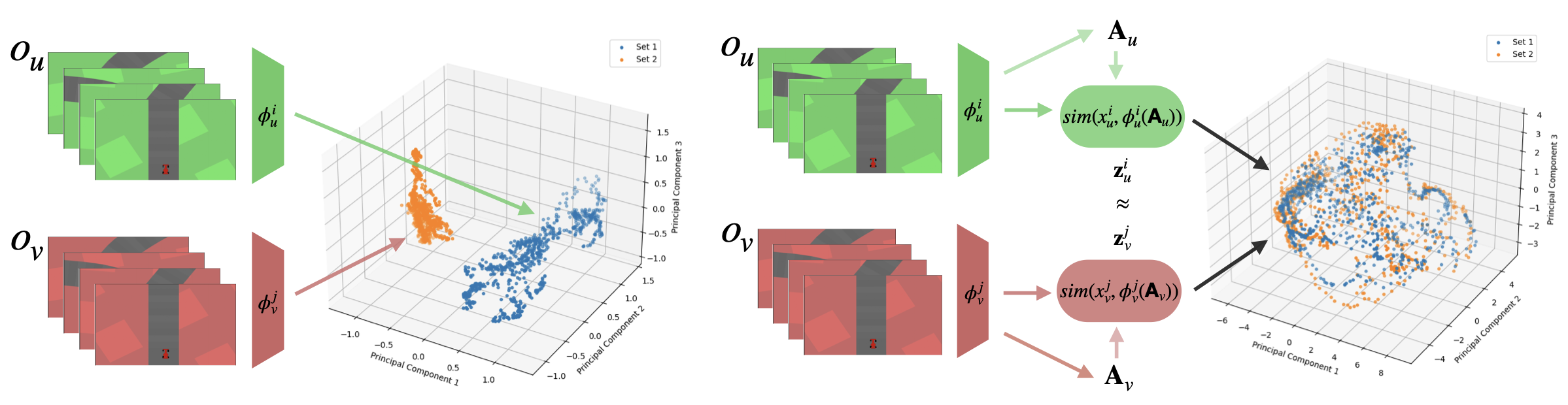
- 2025TL;DR: We adapt relative representations to reinforcement learning, enabling zero-shot composition of encoders and controllers trained independently across different visual variations and task objectives. This achieves 75% reduction in training time (from N×M to N+M models) while maintaining performance comparable to end-to-end training.
- bioRxiv
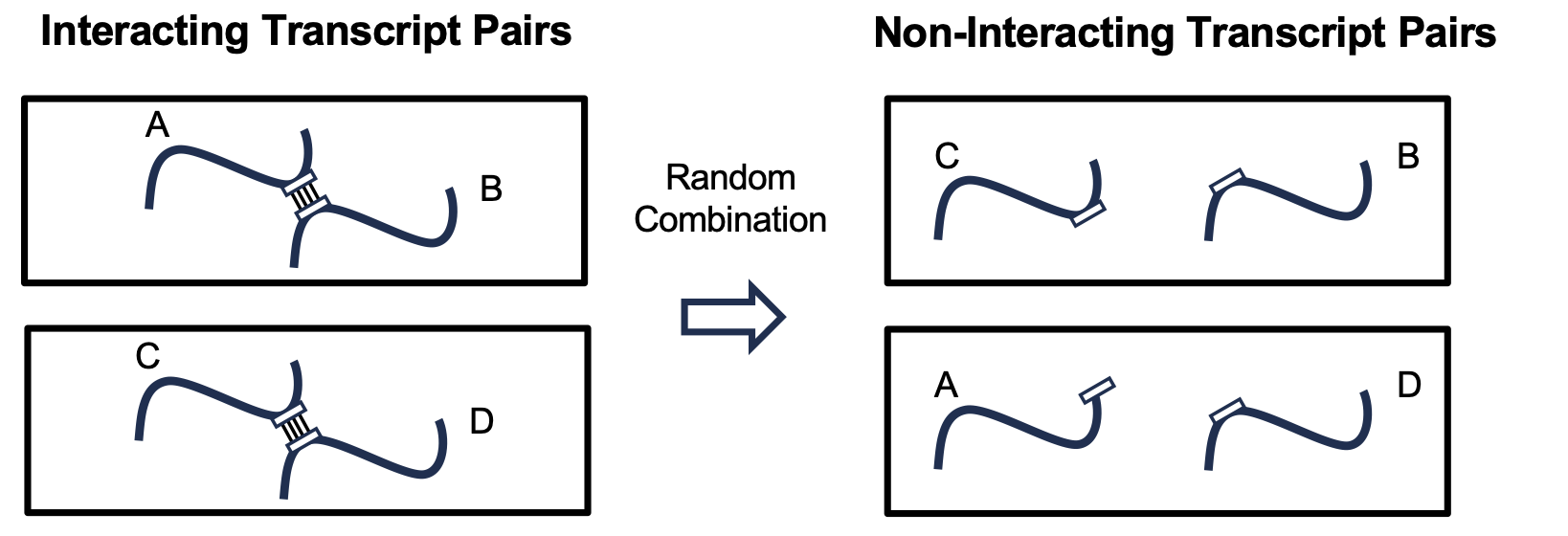 bioRxiv, 2025TL;DR: We identify low-complexity repeats (LCRs) as key drivers of RNA-RNA interactions and develop RIME, a deep learning model using nucleic acid language model embeddings to predict RNA-RNA interactions. RIME outperforms traditional thermodynamics-based tools and successfully captures LCR-mediated interactions important for gene regulation and neuronal development
bioRxiv, 2025TL;DR: We identify low-complexity repeats (LCRs) as key drivers of RNA-RNA interactions and develop RIME, a deep learning model using nucleic acid language model embeddings to predict RNA-RNA interactions. RIME outperforms traditional thermodynamics-based tools and successfully captures LCR-mediated interactions important for gene regulation and neuronal development
2024
- ICLR spotlight
 In International Conference on Learning Representations, 2024TL;DR: We construct a product space of multiple relative representations, each computed using different distance metrics (Cosine, Euclidean, L1, L∞), to capture complex transformations between latent spaces without committing to a single invariance a priori. This consistently matches or exceeds the best single metric across vision, text, and graph domains in zero-shot model stitching tasks.
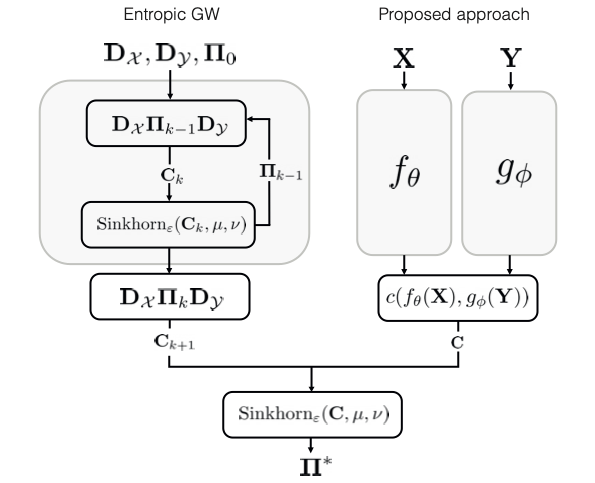
In International Conference on Learning Representations, 2024TL;DR: We construct a product space of multiple relative representations, each computed using different distance metrics (Cosine, Euclidean, L1, L∞), to capture complex transformations between latent spaces without committing to a single invariance a priori. This consistently matches or exceeds the best single metric across vision, text, and graph domains in zero-shot model stitching tasks. - In ICML AI4Science Workshop, 2024TL;DR: We transform the computationally intractable Gromov-Wasserstein problem into a scalable, inductive solution by learning embeddings that map domains into a common space where alignment reduces to a single optimal transport problem. This enables handling 45,000+ samples where standard solvers fail beyond 25,000, with extensions to non-metric structures through rank-based matching.
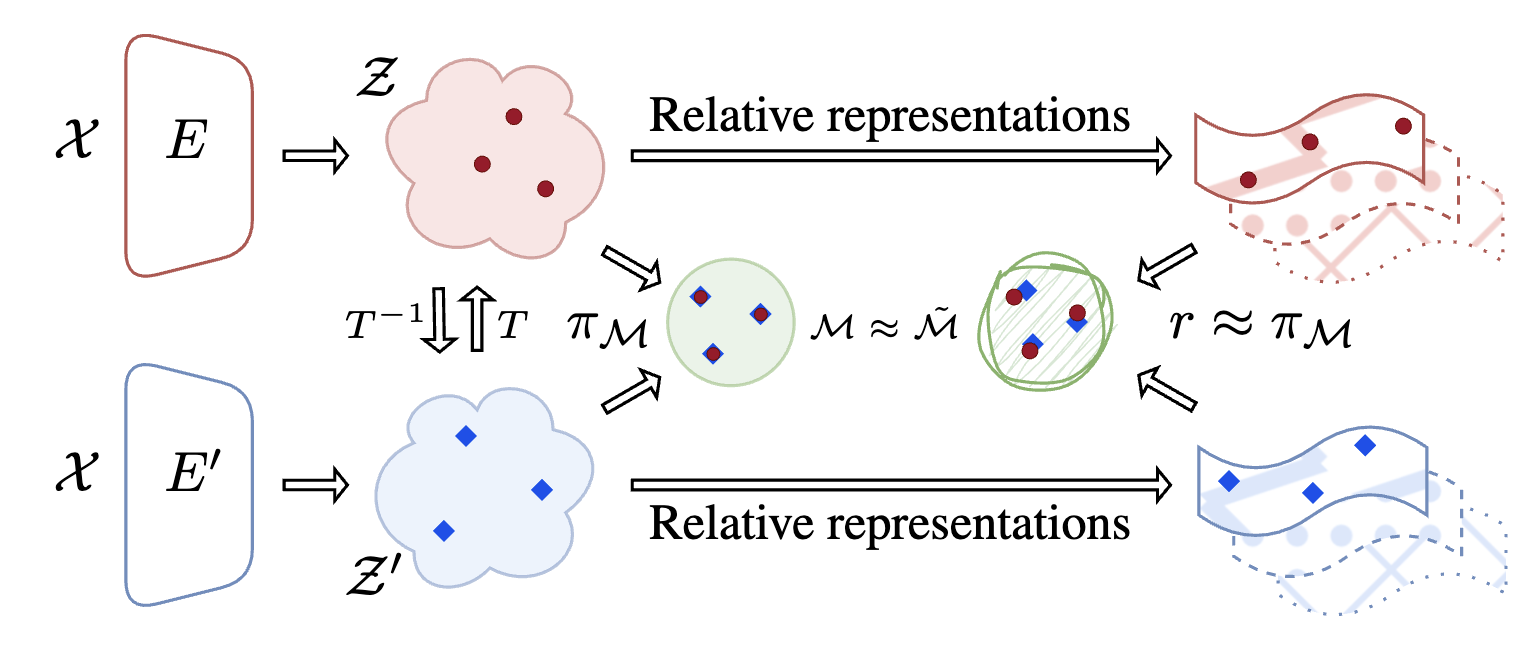
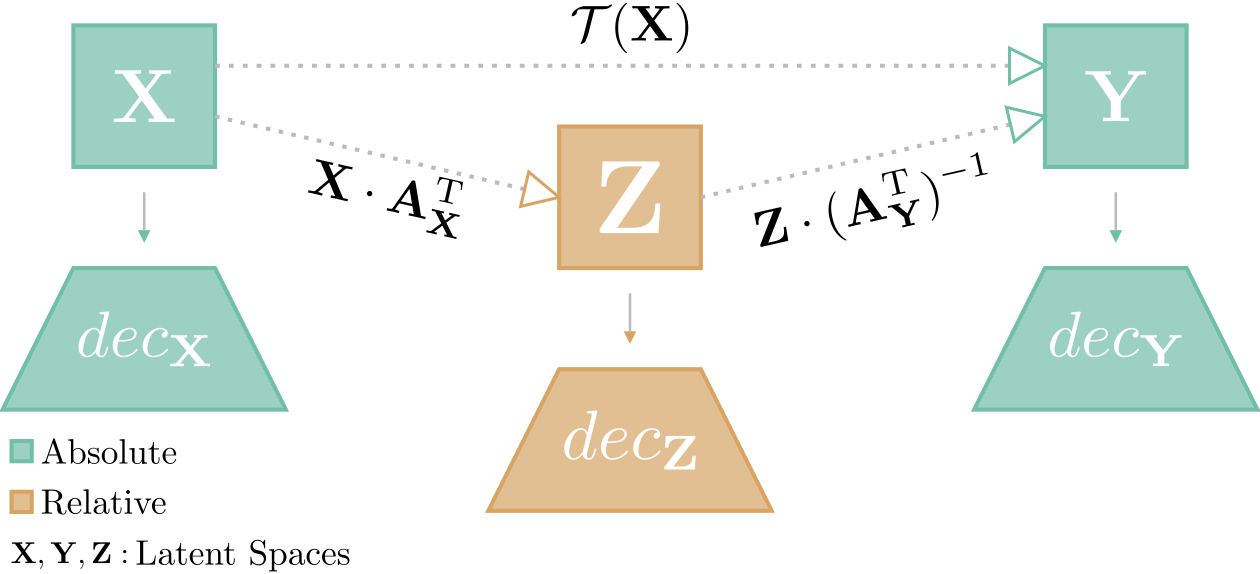
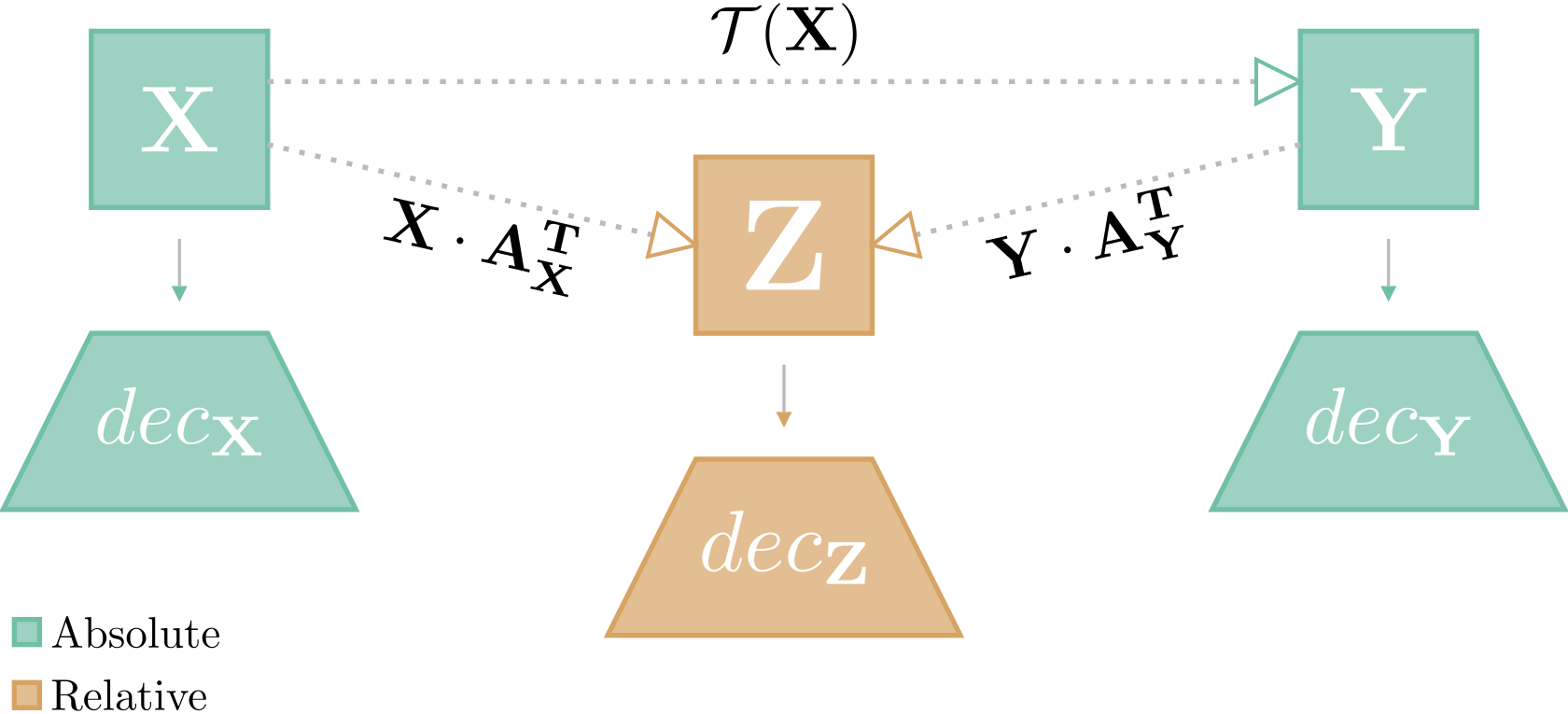
- arXiv, 2024TL;DR: We formalize the inverse transformation from relative space back to absolute space, enabling zero-shot latent space translation without concurrent access to both models or additional training. Combined with the scale invariance properties of neural classifiers, this enables practical model compositionality where pre-trained encoders and classifiers can be mixed and matched across architectures and modalities.
-
 It’s All Relative: Relative Uncertainty in Latent Spaces using Relative RepresentationsIn NeurIPS UniReps Workshop, 2024TL;DR: We address the reparametrization problem in neural network ensemble uncertainty quantification by transforming latent spaces into relative representations. By sampling models along a curve connecting two independently trained networks and measuring alignment with a Fisher-inspired metric, we show that relative spaces reduce overestimated uncertainty and reveal that most meaningful latent changes occur around the curve midpoint
It’s All Relative: Relative Uncertainty in Latent Spaces using Relative RepresentationsIn NeurIPS UniReps Workshop, 2024TL;DR: We address the reparametrization problem in neural network ensemble uncertainty quantification by transforming latent spaces into relative representations. By sampling models along a curve connecting two independently trained networks and measuring alignment with a Fisher-inspired metric, we show that relative spaces reduce overestimated uncertainty and reveal that most meaningful latent changes occur around the curve midpoint -
 Latent Communication for Zero-shot Stitching in Reinforcement LearningIn Seventeenth European Workshop on Reinforcement Learning, 2024TL;DR: We enable zero-shot modular policy reuse in reinforcement learning by learning simple affine transformations (via SVD) between independently trained agents’ latent representations using semantically aligned anchor observations. This allows encoders and controllers from different agents to be stitched together without training, achieving performance comparable to end-to-end training for robust control tasks.
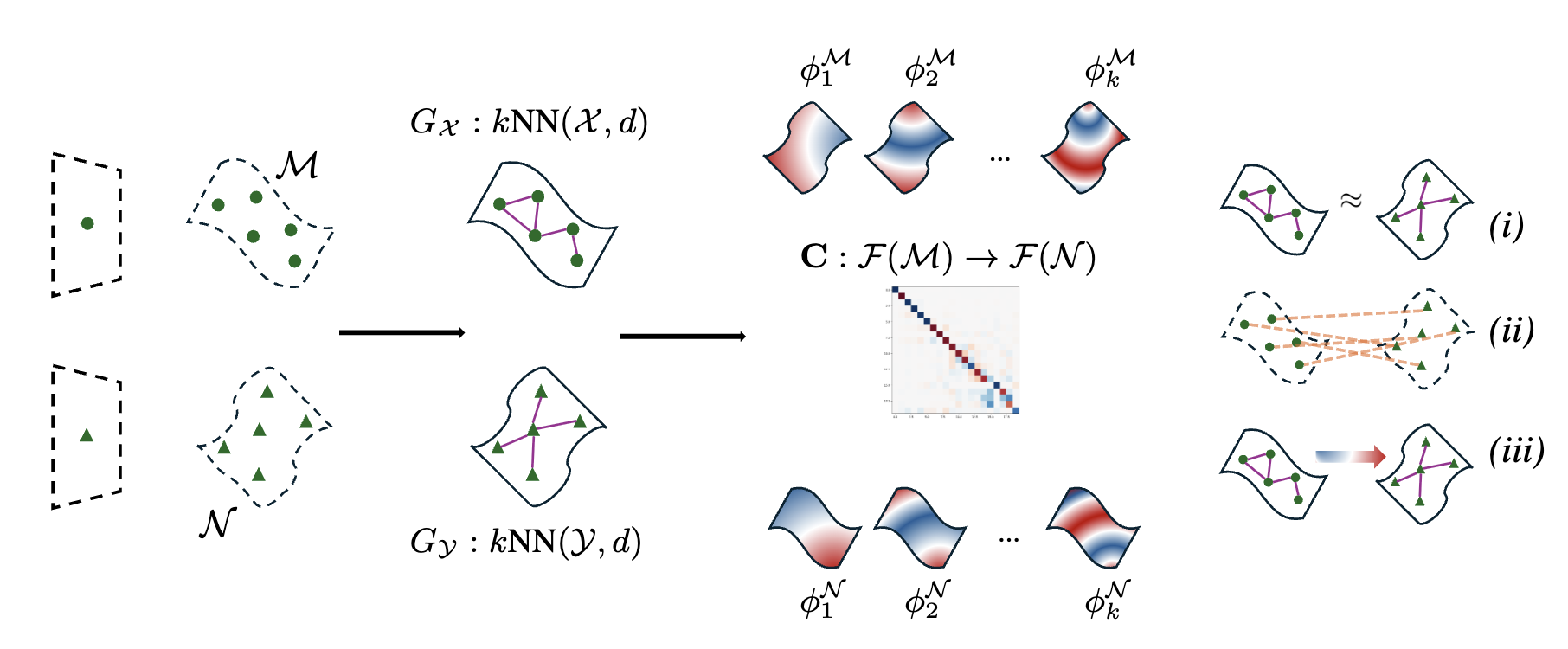
Latent Communication for Zero-shot Stitching in Reinforcement LearningIn Seventeenth European Workshop on Reinforcement Learning, 2024TL;DR: We enable zero-shot modular policy reuse in reinforcement learning by learning simple affine transformations (via SVD) between independently trained agents’ latent representations using semantically aligned anchor observations. This allows encoders and controllers from different agents to be stitched together without training, achieving performance comparable to end-to-end training for robust control tasks. - Latent Functional Maps: a spectral framework for representation alignmentIn Advances in Neural Information Processing Systems, 2024TL;DR: We adapt the functional maps framework from 3D geometry processing to neural latent spaces by computing spectral transformations between graph Laplacian eigenbases. This provides a unified framework that can compare representational spaces, find correspondences with minimal supervision (5-10 anchors), and transfer representations while maintaining interpretability through spectral analysis.
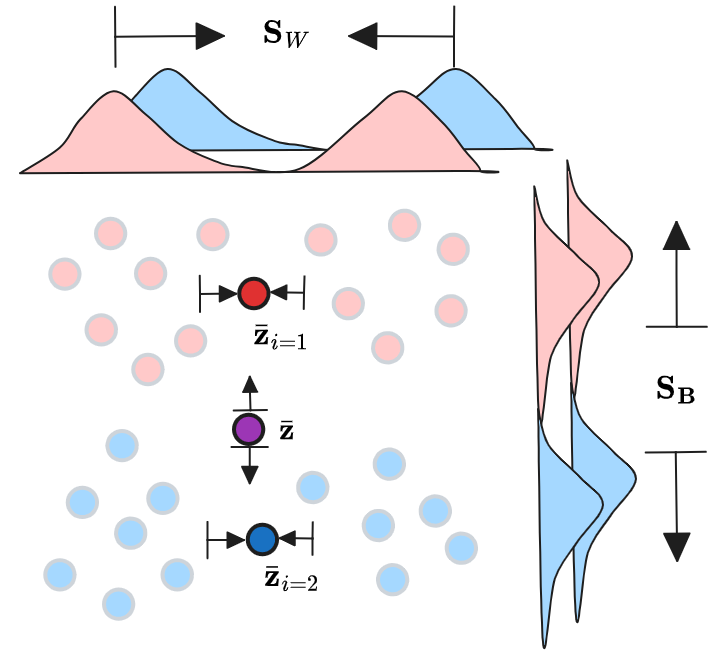
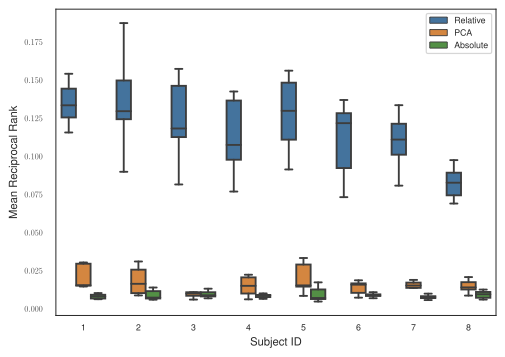
- Multi-subject neural decoding via relative representationsIn COSYNE, 2024TL;DR: We apply relative representations to neural decoding, mapping fMRI data from different subjects into a common subject-agnostic representational space by leveraging neural encoders and anchor-based similarity functions. On the Natural Scenes Dataset with 8 subjects, our framework achieves substantially higher cross-subject retrieval accuracy than PCA and absolute baselines, enabling generalization without expensive alignment training
2023
- ICLR oral
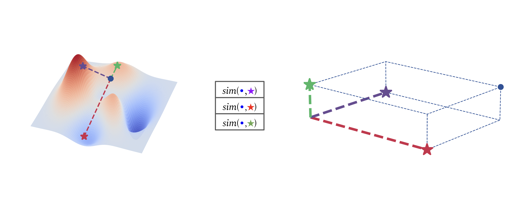 In International Conference on Learning Representations, 2023TL;DR: We introduce relative representations that make neural network latent spaces invariant to training stochasticity by encoding data points relative to anchor samples using cosine similarity. This enables zero-shot model stitching across different random seeds, architectures, languages, and datasets without any training.
In International Conference on Learning Representations, 2023TL;DR: We introduce relative representations that make neural network latent spaces invariant to training stochasticity by encoding data points relative to anchor samples using cosine similarity. This enables zero-shot model stitching across different random seeds, architectures, languages, and datasets without any training. - In Advances in Neural Information Processing Systems, 2023TL;DR: ASIF creates multimodal models without any training by using relative representations computed from frozen pre-trained unimodal encoders and a small collection of image-text pairs. This training-free approach achieves competitive zero-shot classification with 250× less data than CLIP, while providing built-in interpretability.
- In Advances in Neural Information Processing Systems, 2023TL;DR: We enable zero-shot stitching of independently trained encoders and decoders by estimating simple transformations (orthogonal via Procrustes analysis) between their latent spaces using semantically aligned anchor points. This works across architectures, domains, and even modalities without requiring training on relative representations.
-
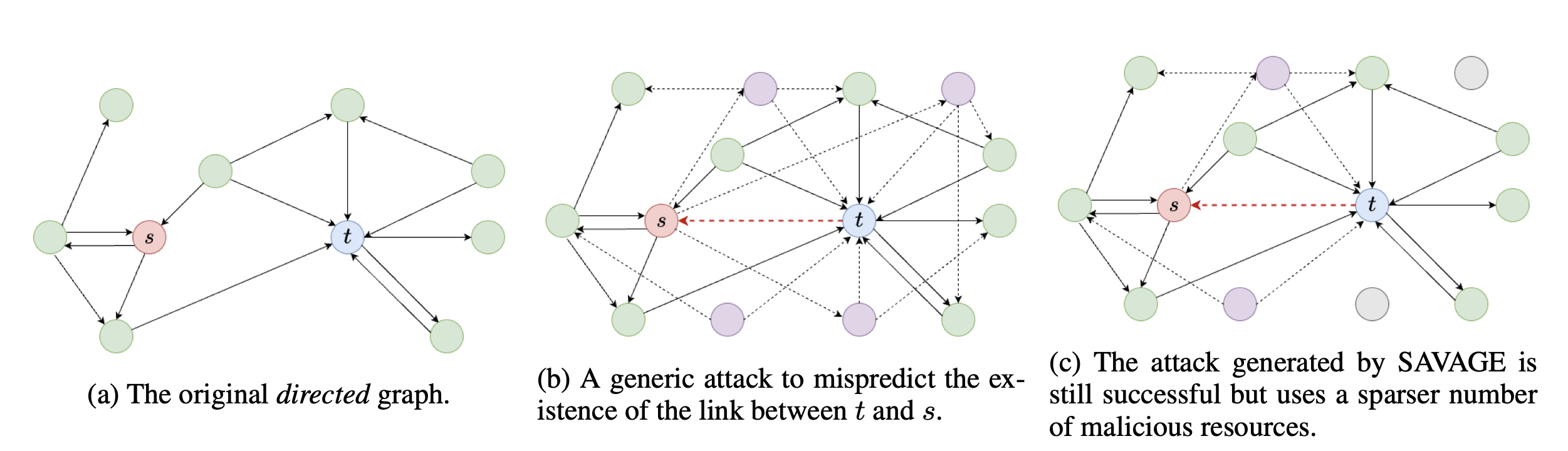 IEEE Transactions on Artificial Intelligence, 2023TL;DR: We introduce SAVAGE, an adversarial attack framework that manipulates GNN-based link prediction in social networks by strategically injecting minimal malicious nodes with a sparsity-enforcing mechanism. The attacks achieve optimal trade-off between success rate and resource usage while transferring effectively across different black-box link prediction methods
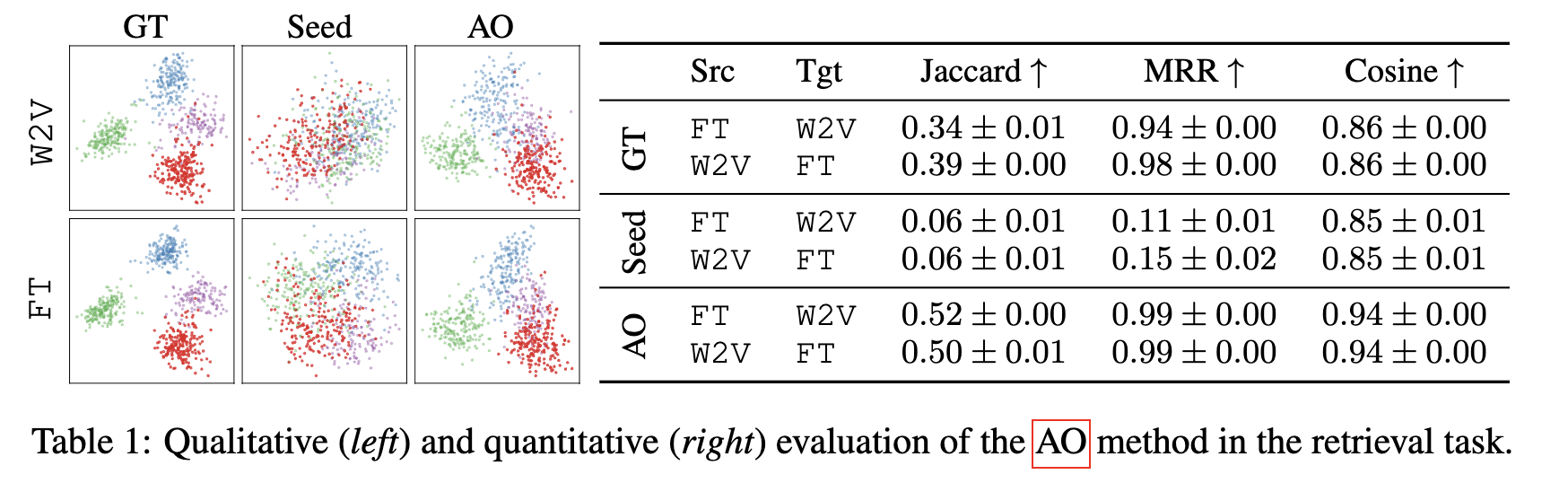
IEEE Transactions on Artificial Intelligence, 2023TL;DR: We introduce SAVAGE, an adversarial attack framework that manipulates GNN-based link prediction in social networks by strategically injecting minimal malicious nodes with a sparsity-enforcing mechanism. The attacks achieve optimal trade-off between success rate and resource usage while transferring effectively across different black-box link prediction methods - Bootstrapping Parallel Anchors for Relative RepresentationsarXiv, 2023TL;DR: We reduce the number of required parallel anchors for relative representations by one order of magnitude through an optimization-based method that discovers new anchors from a minimal seed set. Starting with just 15 seed anchors, our method discovers 300 parallel anchors and often outperforms using ground truth anchors.
- ICLR Tiny Papers Track, 2023TL;DR: We discover that unexpected (low-likelihood) tokens cause transformer models to attend less to information from themselves when computing representations, particularly in higher layers. This correlation between token likelihood and attention values has implications for assessing LLM robustness in real-world scenarios
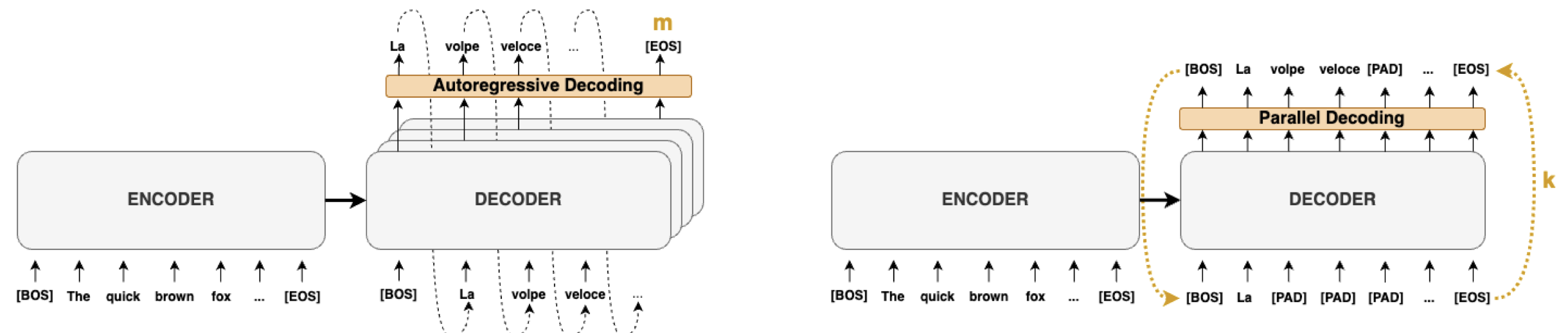
- In Annual Meeting of the Association for Computational Linguistics, 2023TL;DR: We accelerate transformer inference for translation by reformulating standard greedy autoregressive decoding as parallel fixed-point iteration using Jacobi and Gauss-Seidel methods, achieving 38% speedup (nearly 2× on parallel hardware) while maintaining translation quality without any model retraining or architectural changes
-
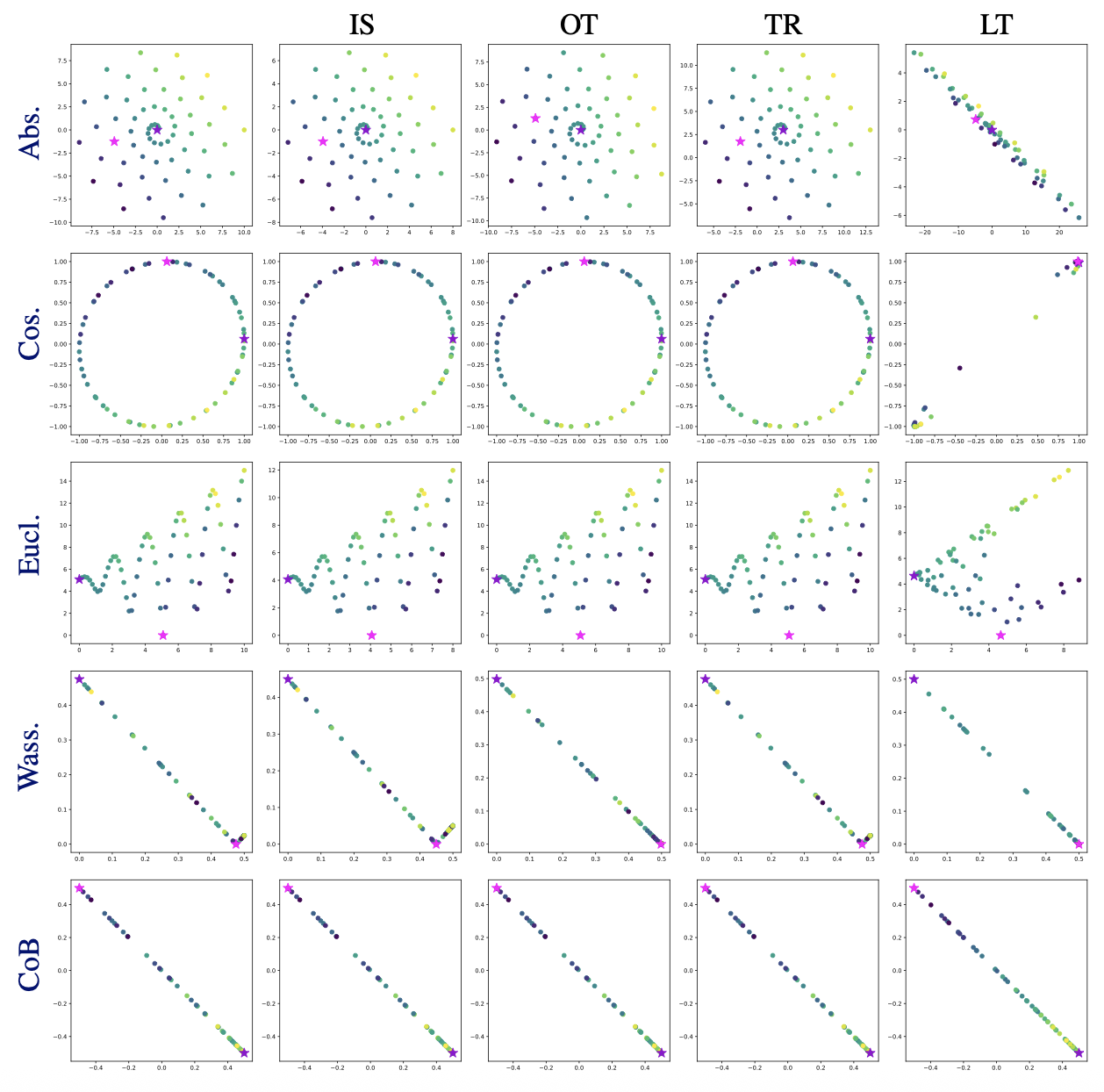 In ICML TAG-ML Workshop, 2023TL;DR: We propose a framework for incorporating invariances to targeted transformations (model initialization, architecture, training modality) into neural representations, demonstrating that independently trained networks have structural similarities in latent spaces. Analysis across 8 benchmarks reveals that optimal transformation classes depend on the task at hand
In ICML TAG-ML Workshop, 2023TL;DR: We propose a framework for incorporating invariances to targeted transformations (model initialization, architecture, training modality) into neural representations, demonstrating that independently trained networks have structural similarities in latent spaces. Analysis across 8 benchmarks reveals that optimal transformation classes depend on the task at hand
2022
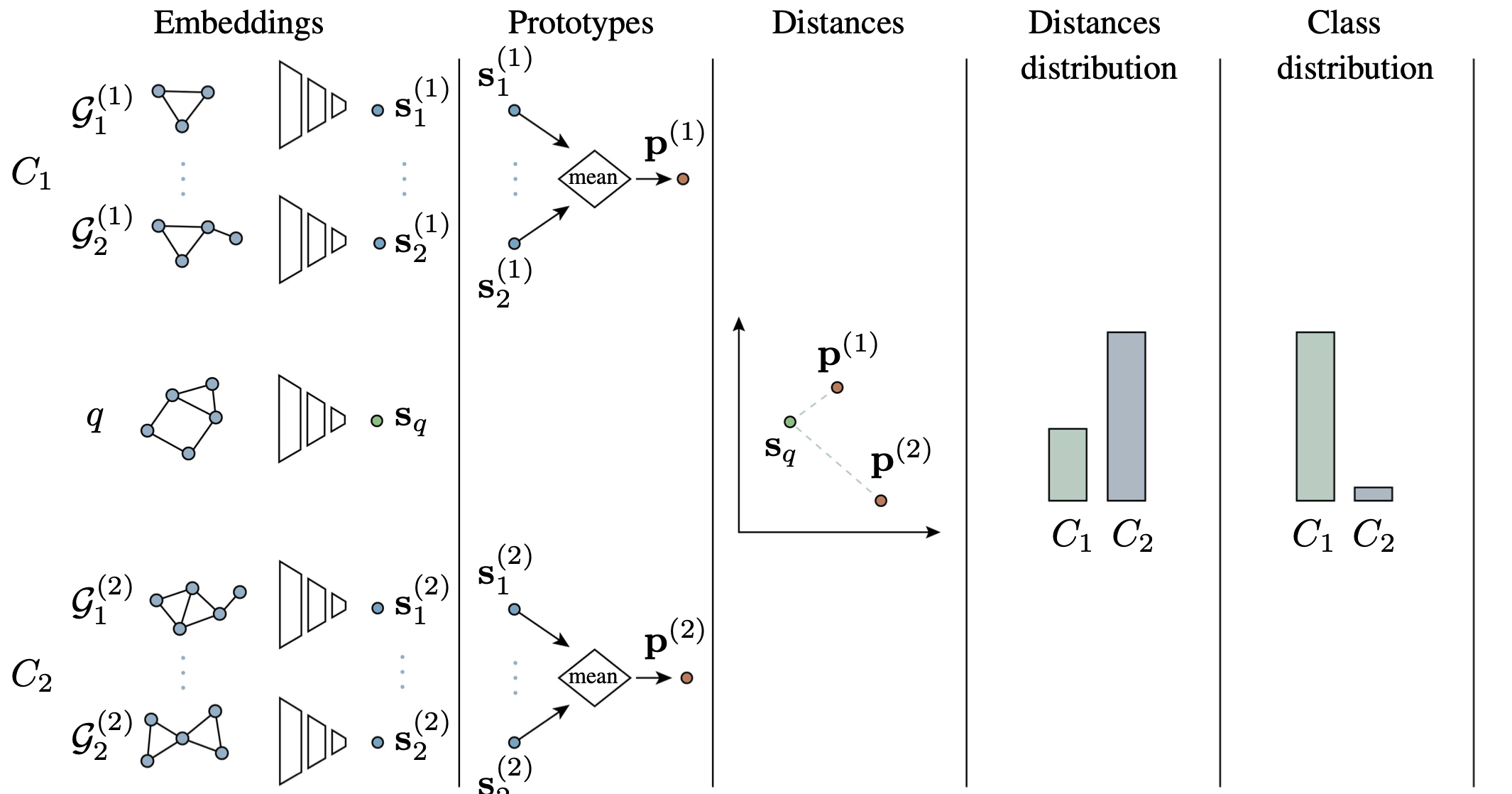
- In Learning on Graphs Conference, 2022TL;DR: We provide a unified evaluation framework for few-shot graph classification, showing that simple metric learning baselines with state-of-the-art graph embedders and task-conditioned embedding spaces outperform complex graph-specific approaches. Our modular framework with MixUp data augmentation achieves best overall results across benchmarks
2021
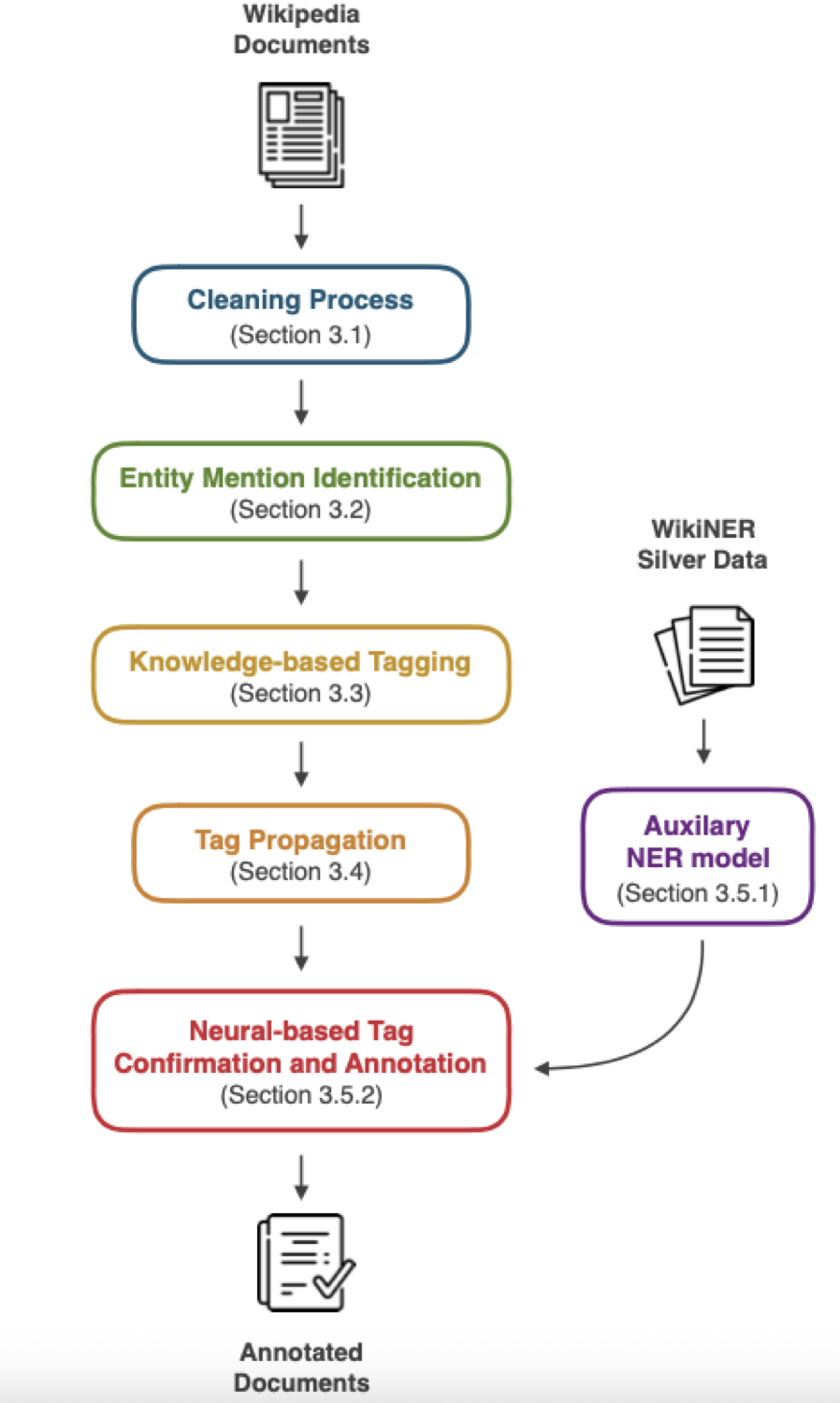
- In Conference on Empirical Methods in Natural Language Processing, 2021TL;DR: We create high-quality silver (automatically labeled) training data for multilingual Named Entity Recognition by combining knowledge-based approaches from Wikipedia with neural models and a novel domain adaptation technique, achieving 6 F1-score point improvement over previous state-of-the-art data creation methods