Valentino Maiorca
Postdoctoral Researcher at ISTA | ex-Apple MLR Intern

I’m interested in how the semantics of data shape the latent geometry of neural networks and enable information transfer between them.
I study how to act on this shared geometry, from aligning representational spaces to steering them toward task-relevant properties. The goal is to understand better what models learn and how to control, transfer, or repurpose that knowledge.
I’m always open to collaborations, discussions, and new ideas, so feel free to contact me!
selected publications
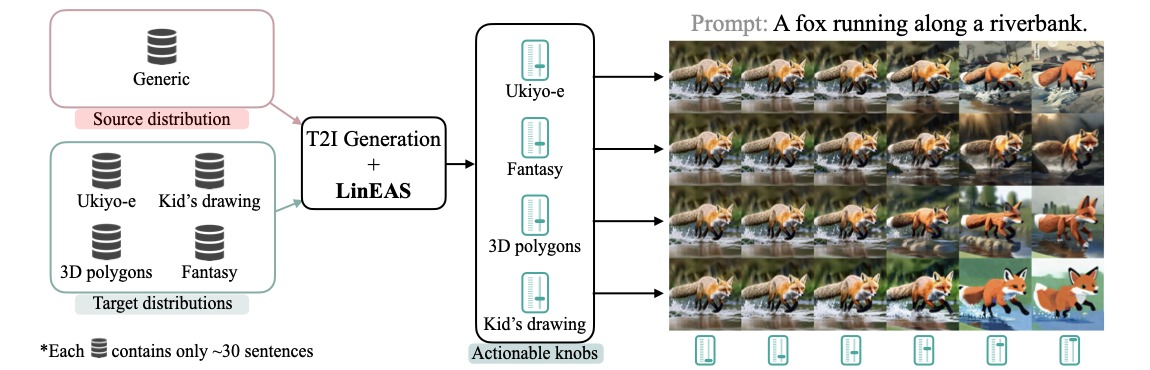
- In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025TL;DR: We introduce LinEAS, a method for controlling generative models by learning affine transformations on internal activations using optimal transport theory. Training end-to-end across all layers with just 32 unpaired samples and sparse regularization for automatic neuron selection, LinEAS achieves effective toxicity mitigation in LLMs and style control in text-to-image models without retraining
- NeurIPS spotlight
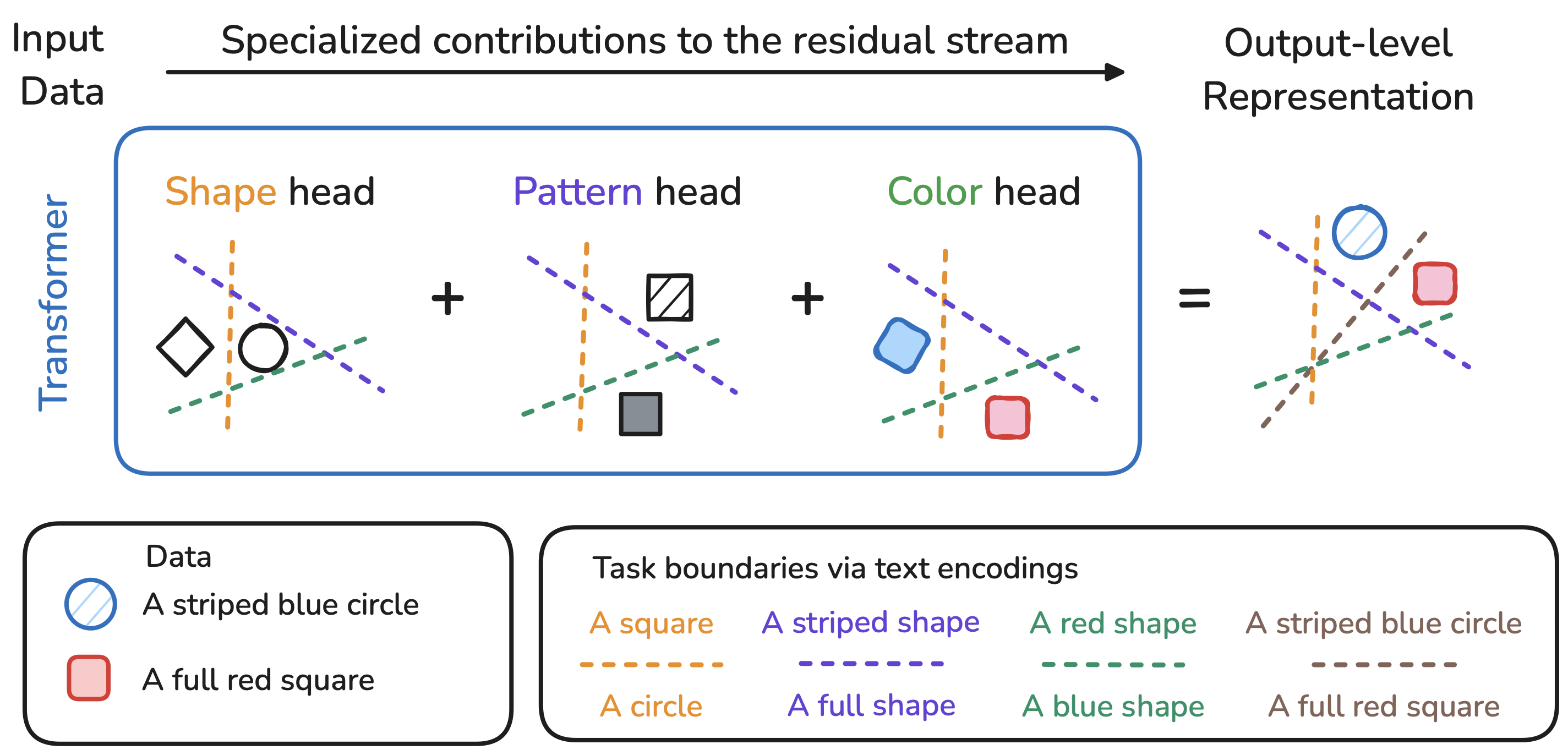
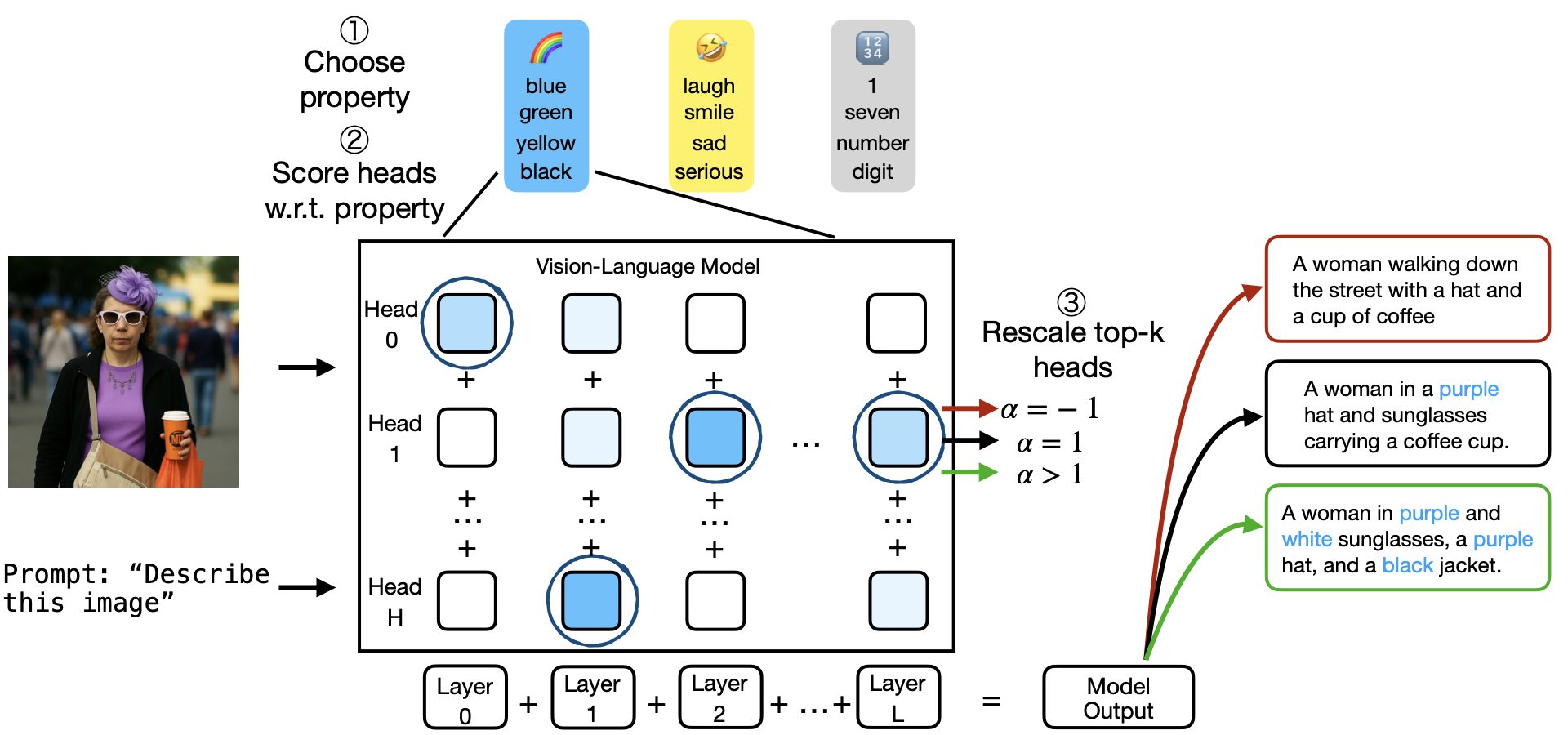 In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025TL;DR: We use Simultaneous Orthogonal Matching Pursuit to identify attention heads specialized in narrow semantic domains (colors, countries, toxicity) in large language and vision-language models. Intervening on as few as 1% of heads enables bidirectional concept control—suppressing toxic content by 34-51% or enhancing target attributes—without any training
In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025TL;DR: We use Simultaneous Orthogonal Matching Pursuit to identify attention heads specialized in narrow semantic domains (colors, countries, toxicity) in large language and vision-language models. Intervening on as few as 1% of heads enables bidirectional concept control—suppressing toxic content by 34-51% or enhancing target attributes—without any training - TMLR, 2025TL;DR: We discover that attention head representations in vision transformers lie on low-dimensional manifolds where principal components encode specialized semantics (letters, locations, animals, etc.). By selectively amplifying task-relevant principal components through learned anisotropic scaling (ResiDual), we achieve fine-tuning level performance with up to 4 orders of magnitude fewer parameters than full fine-tuning.
- ICLR oral
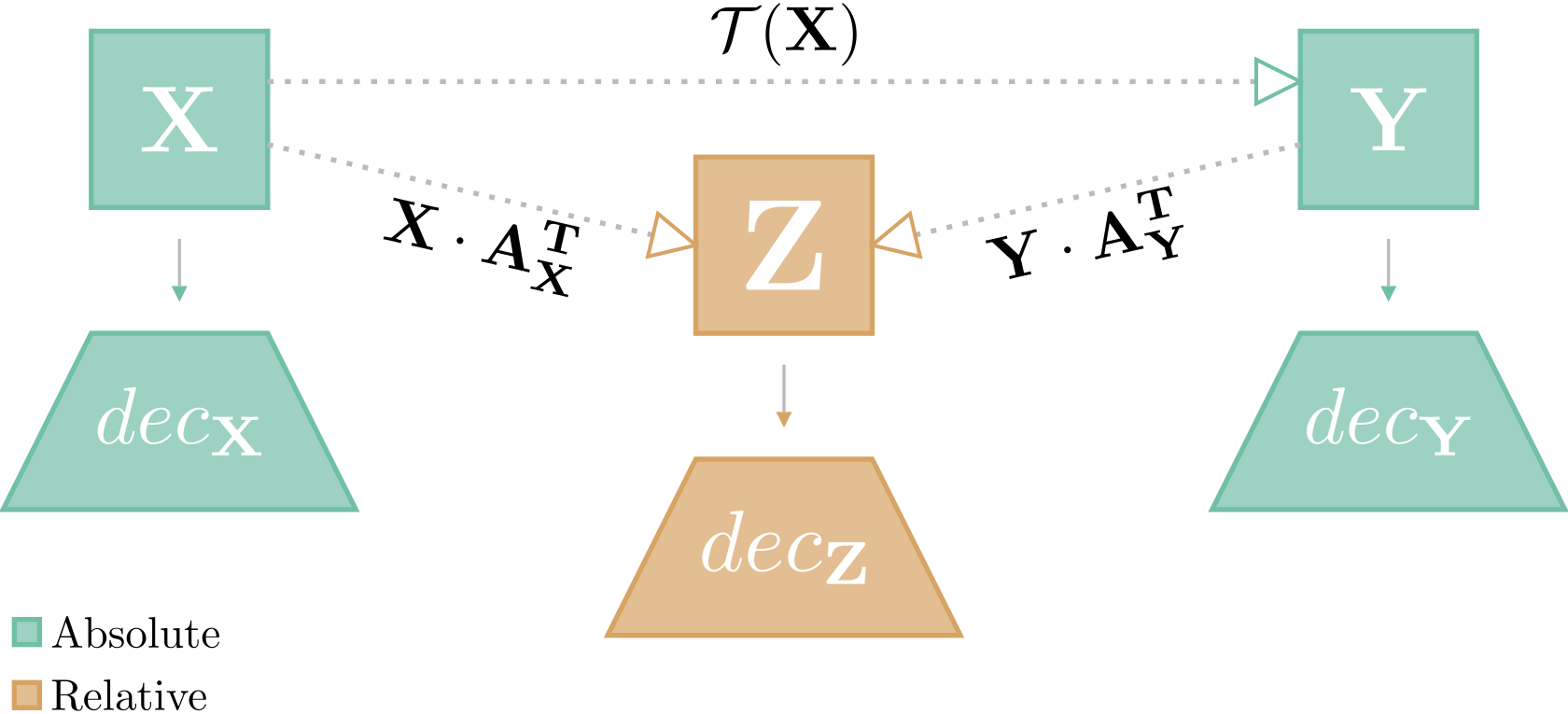
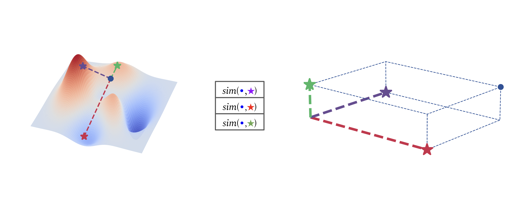 In International Conference on Learning Representations, 2023TL;DR: We introduce relative representations that make neural network latent spaces invariant to training stochasticity by encoding data points relative to anchor samples using cosine similarity. This enables zero-shot model stitching across different random seeds, architectures, languages, and datasets without any training.
In International Conference on Learning Representations, 2023TL;DR: We introduce relative representations that make neural network latent spaces invariant to training stochasticity by encoding data points relative to anchor samples using cosine similarity. This enables zero-shot model stitching across different random seeds, architectures, languages, and datasets without any training. - In Advances in Neural Information Processing Systems, 2023TL;DR: ASIF creates multimodal models without any training by using relative representations computed from frozen pre-trained unimodal encoders and a small collection of image-text pairs. This training-free approach achieves competitive zero-shot classification with 250× less data than CLIP, while providing built-in interpretability.
- In Advances in Neural Information Processing Systems, 2023TL;DR: We enable zero-shot stitching of independently trained encoders and decoders by estimating simple transformations (orthogonal via Procrustes analysis) between their latent spaces using semantically aligned anchor points. This works across architectures, domains, and even modalities without requiring training on relative representations.
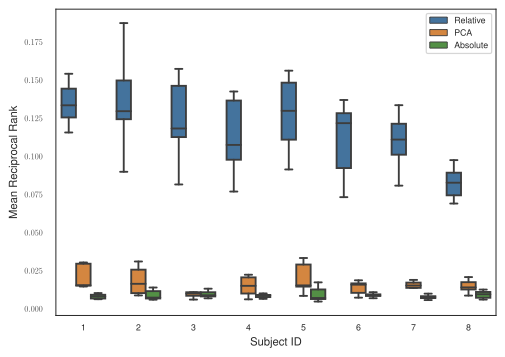
- Multi-subject neural decoding via relative representationsIn COSYNE, 2024TL;DR: We apply relative representations to neural decoding, mapping fMRI data from different subjects into a common subject-agnostic representational space by leveraging neural encoders and anchor-based similarity functions. On the Natural Scenes Dataset with 8 subjects, our framework achieves substantially higher cross-subject retrieval accuracy than PCA and absolute baselines, enabling generalization without expensive alignment training